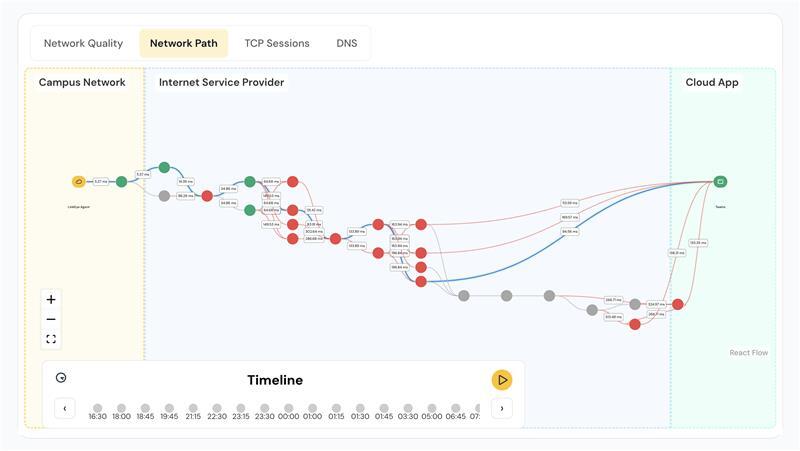
In today’s distributed, software-defined networks, complexity is the norm. Distributed offices, hybrid infrastructure, evolving compliance needs, and a flood of connected devices make proactive network management a necessity.
According to Incognito, nearly 45% of service providers identify network monitoring and troubleshooting as their top AI use‑case, driving improved customer satisfaction and cost efficiencies. And yet, when something breaks, the most common first step is to raise a support ticket and wait. (Source: Incognito’s “New research reveals the role of AI in revolutionizing network operations for service providers”)
AI-powered diagnostics is reshaping that response. Instead of relying solely on manual investigation, diagnostics now run autonomously. With built-in test logic and contextual analysis, systems can pinpoint what’s gone wrong, why it happened, and what needs to be done, even before an engineer logs in.
Actions-focused Diagnostics
The traditional approach to troubleshooting involved wading through dashboards, guessing at correlations, and escalating tickets just to “look into it.” But with LinkEye’s intelligent co-pilot built into the system, troubleshooting gets automated.
Once network health starts to dip, instead of just triggering alerts, it automatically initiates diagnostic test workflows tuned to the specific symptoms observed: whether it’s latency, packet loss, misconfiguration, or link degradation.
The results? A clear root cause analysis, mapped against the baseline, with an actionable plan that tells teams what changed, what failed, and what to fix. No guesswork required.
Why AI-Powered Diagnostics are Becoming Non-Negotiable
The rise of AIOps has positioned AI diagnostics as a core capability. Multiple studies and vendor reports show:
- Up to 70% faster RCA (root cause analysis)
- 90%+ first-pass accuracy in diagnosing known network problems
- 50% fewer support escalations through intelligent triage
- Shrink alert volume through 80–90% noise suppression
- Reduced dependency on senior engineers for day-to-day issues
As Gartner and Forrester have noted, diagnostics powered by AI are now one of the top-ranked use cases in network operations, especially in environments where downtime translates directly into revenue loss or SLA penalties. These numbers reflect a fundamental shift in how Network Operations teams work. With the right diagnostic system in place, even a junior support engineer can resolve issues that used to require multiple escalations.
Key Capabilities of LinkEye’s Diagnostic Intelligence
Behind the scenes, LinkEye’s AI-powered diagnostics ties together a series of foundational capabilities that make this speed and precision possible:
- Proactive Detection: Issues are identified before they affect end-users based on continuous telemetry and performance baselining.
- Performance Baselining: The system monitors each device against defined thresholds and auto-triggers diagnostics when deviations occur.
- Targeted Testing and RCA: Tests are scoped to the nature of the anomaly such as link performance, device config, app-level metrics, and mapped to specific failure points.
- Plain-Language Plans of Action: Instead of raw data, engineers get a clear explanation of what failed and what action is required.
- Deeper Visibility Across Sites: Multi-site, multi-vendor environments are visualized in one plane, making RCA easier even when the issue spans physical and virtual layers.
- Faster Recovery: Automated configuration backups ensure teams can revert safely if changes break something.
- Consistent Compliance: Misconfigurations, policy violations, or unsanctioned changes are flagged, and in some cases, auto-reverted to preserve baseline integrity.
- Vendor-Agnostic & Future-Ready: SNMP, API, and streaming telemetry support ensures coverage across legacy devices, modern stacks, and what’s coming next.
With structured test flows and actionable insights, AI-powered diagnostics are eliminating friction, surfacing clarity, and moving from reactive to intelligent operations; allowing network teams to gain efficiency and resilience. This is the first step toward self-healing infrastructure when diagnostics are intelligent, remediation becomes automatable.
Final Takeaway: Stop Guessing, Start Diagnosing
The ability to troubleshoot faster and smarter is redefining what network operations can look like. Today, that might mean a clear RCA and a plan of action. Tomorrow, it could mean autonomous resolution based on policy and risk thresholds.
In a world where SLAs are tight, users are distributed, and incidents are expensive, the question remains on how much guesswork can your team afford? With a co-pilot that runs diagnostics, identifies the root cause, and recommends a next step, network operations can always be a step ahead.
When downtime is expensive and user experience is non-negotiable, the smartest move is to stop waiting for L1 and let intelligent diagnostics take the lead.