AI That Knows What’s Not Broken
Every outage has a post-mortem, every recovery has a report, but when everything runs smoothly, the silence makes operations teams uneasy. It’s a fair instinct because modern networks now evolve faster than the rules built to observe them.
According to Dynatrace, 88% of enterprises say their tech stack has grown more complex in the past year, driving an explosion of telemetry. LogicMonitor reports that 63% of operations teams face more than 1,000 alerts every day, and 22% handle over 10,000, so when the noise stops, quiet feels suspicious.
Stability is the signal modern networks must reveal to be understood
Firmware updates, shifting topologies, and dynamic workloads continually rewrite what “healthy” looks like. A CPU usage spike that once raised alarms might now reflect normal demand. As digital systems outpace human oversight, stability itself has become the new frontier of observability, and AI is emerging as the key to knowing not just what’s broken, but what’s not.
How AI Redefines Stability in Modern Observability
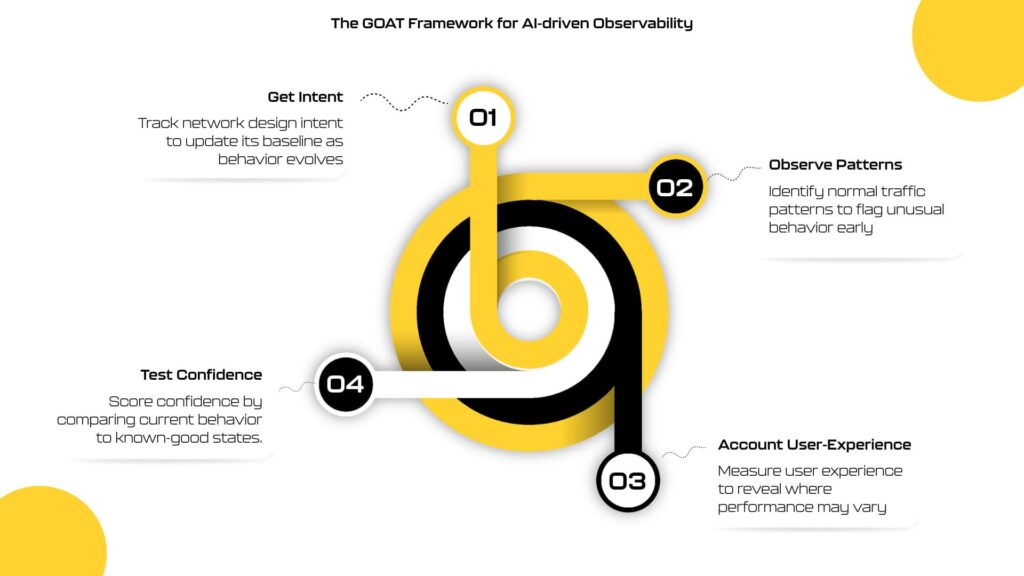
Modern infrastructure doesn’t fail the way it used to. Incidents now surface as subtle shifts in performance, configuration, or traffic patterns that quietly accumulate until something breaks. AI-assisted NetOps platforms like LinkEye are built not just to detect anomalies, but to understand the difference between change and instability. The following four principles, together forming the GOAT framework for AI-driven observability, capture how operational stability is being redefined, measured, and proven.
1. Get Intent
When intent, behavior, and user experience converge, the network’s operational state reveals itself.
A network’s baseline starts with its design intent, i.e., how devices, policies, and paths are meant to operate together. AI models this intent against live network behavior, resulting in a dynamic baseline that reflects both the design and how the network performs, minimizing drift between the two.
2. Observe Patterns
Every network has a natural rhythm. Nightly backups, end-of-week spikes, workload migrations, and even after-hours firmware pushes. AI learns these patterns to distinguish expected change from emerging instability, giving teams early visibility into issues long before they surface.
3. Account User-Experience
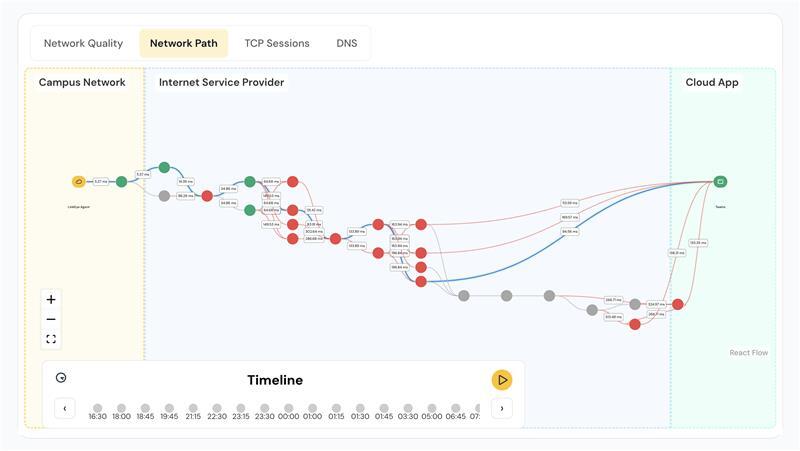
Stability isn’t proven by uptime but by how consistently users experience applications as designed. As services span clouds, ISPs, and SaaS providers, each link in the chain must behave predictably. LinkEye’s DX Agent uses synthetic path testing to model those journeys and visualize performance across every domain, isolating where instability originates, making user experience a measurable form of stability.
4. Test Confidence
AI quantifies how closely current conditions align with validated, known-good behavior. High confidence indicates predictable operation; low confidence exposes uncertainty and directs investigation before performance degrades. Confidence scoring makes operational stability verifiable. Teams can prove stability, anticipate stress, and demonstrate that the network is performing as designed.
The Near Future: Stability You Can Trust
Only alignment to a validated state quantifies stability as a verifiable operational metric.
As AI becomes intrinsic to observability, it adds an intelligence layer that interprets behavior, aligns operations with design intent, and quantifies confidence in real time, making stability a measurable indicator of digital maturity and business reliability.
Enterprises adopting AI-assisted observability are already seeing the results: 79% less downtime (New Relic, 2024), 2.6x annual return on observability investments (Splunk, 2024), and a new level of predictability across complex systems. The lesson is clear–observability that understands stability doesn’t just reduce risk; it builds trust in the systems that run the business.